Indexace stránek je základním předpokladem pro úspěch v SEO. Pokud vyhledávače neví o URL z vašeho webu, nemohou je zobrazit v rámci výsledků vyhledávání. Často se také stává, že vyhledávače některé stránky nebo určité segmenty webu z nějakého důvodu jednoduše neindexují.
URL, které nejsou indexované, můžete najít pomocí Mineru Fulltext Index Checker, který vám kromě jiného pomůže odhalit také příčinu, proč není vaše stránka indexovaná.
Vyhledávače totiž hromadnou kontrolu indexace neumožňují. Nástroje jako Seznam Reporter či Google Search Console ukazují pouze základní statistiku počtu indexovaných URL a operátor site: neposkytuje 100% spolehlivá data.
Využití v praxi
Miner kontroly indexace stránek využijete v případě:
- Pokud začínáte pracovat na novém projektu a pracujete na úvodním SEO auditu stránky. Jedním z hlavních kroků je zjistit, zda jsou potřebné stránky v pořádku indexované.
- Zaznamenali jste propad pozic, případně nižší nebo žádnou návštěvnost z přirozeného vyhledávání na konkrétní stránku a potřebujete zjistit, jestli stránka náhodou nevypadla z indexu vyhledávače.
- Pokud máte pochybnosti o stavu indexace svého webu.
- Pokud dojde k zásadním výkyvům křivky indexace například v Google Search Console. Čím dříve se vám podaří zjistit, které URL se přestaly indexovat, tím dřív můžete odhalit příčinu a zapracovat na jejím odstranění.
Pojďme ale pěkně od základů.
Co je index vyhledávačů
V první řadě je třeba pochopit, co je to index vyhledávače. Vyhledávače denně prochází miliardy stránek různých webů a stahují si jejich obsah. Pouze zlomek tohoto obsahu je ale pro ně důležitý a využitelný ve výsledcích vyhledávání.
Indexem se na straně vyhledávačů většinou myslí databáze obsahu, který si vyhledávač uloží a používá jej ve výsledcích vyhledávání.
Může být zaindexovaná stránka vyřazena z indexu
Ano, může se stát, že stránka, která již bylo jednou zaindexovaná, se vyřadí z indexu. Nejčastěji to způsobují následující příčiny:
- Stránka přestala fungovat a začala vracet chybový stavový kód (40x), nebo serverovou chybu (50x) na kterou crawler narazil již vícekrát při průchodu webem
- Na stránku se nasadila direktiva pro roboty noindex
- Vyhledávač vyhodnotil, že danou stránku nepoužívá ve výsledcích vyhledávání a je na ni minimum nebo nezajímavý obsah a proto stránku vyřadil z indexu
Pokud narazíte na to, že některé z vašich stránek není zaindexovaná, doporučuji využít miner na kontrolu indexovatelnosti, který vám může pomoci odhalit, proč daná stránka není zaindexovaná.
Kontrola indexace URL ve vyhledávačích
Ke kontrole toho, jestli je nějaká URL zaindexovaná ve vyhledávačích, lze využít přímo vyhledávače nebo jejich nástroje:
Kontrola indexace na Seznam
Na kontrolu indexace stránky na Seznamu, můžete použít operátor info: a za ním URL adresu, kterou chcete kontrolovat. Stačí tedy do vyhledávání vložit například:
info:https://www.marketingminer.com/cs
Pokud se daná stránka zobrazí ve výsledcích vyhledávání, znamená to, že je stránka na Seznamu zaindexovaná.
Pokud stránka není zaindexovaná a potřebujete ji rychle dostat do indexu, můžete použít tento nástroj: https://search.seznam.cz/wt/pridej-stranku kam pouze vložíte URL adresu a pošlete ji k zaindexování:
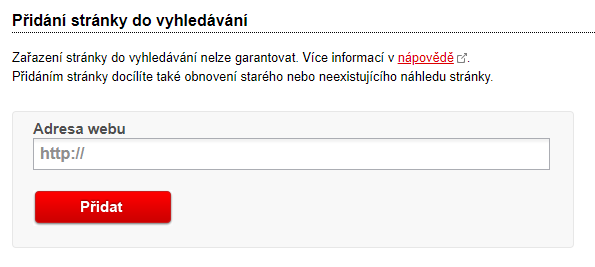
Pokud SeznamBot vyhodnotí, že je pro něho stránka zajímavá, tak i zaindexuje a začne zobrazovat ve výsledcích vyhledávání.
Kontrola indexace na Google
Nejrychlejší způsob, jakým se dá na Google zkontrolovat, zda je konkrétní URL zaindexovaná, bylo dříve použít také operátor info:.
Bohužel koncem března roku 2019 Google přestal podporovat operátor info: a proto už takovýmto způsobem není možné 100% ověřit indexaci jakéhokoli webu. Více informací k této problematice jsme sepsali v článku:
https://www.marketingminer.com/cs/blog/google-podpora-operatoru-info.html
Ruční kontrola indexace stránek v GSC
Pokud tedy chcete ručně zkontrolovat indexaci menšího množství stránek, můžete využít URL inspection tool v Google Search Console.
Stačí vložit URL, kterou chcete zkontrolovat a pokud je na vašem na webu, ke kterém máte ověřeno vlastnictví v GSC, tak vám zobrazí detailní informace o její indexaci:
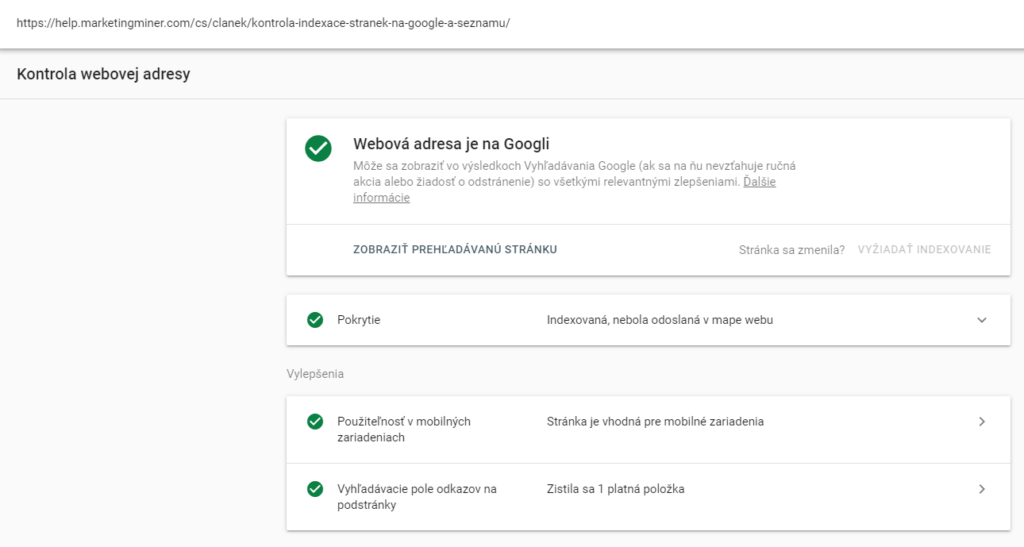
Co ale v případě, kdy máte tisícovky vstupních stránek a chcete zkontrolovat hromadně jejich indexaci? Tak přesně v takovém případě vám pomůže miner Fulltext Index Checker.
Jak hromadně zkontrolovat indexaci webu
Po přihlášení do Marketing Mineru klikněte vpravo nahoře na tlačítko Vytvořit report. Budeme kontrolovat indexaci URL, takže jako vstup zvolíme URL.
Následně do schránky napíšete nebo vložíte seznam URL, jejichž indexaci chcete zjistit.
Aby byl váš report jednoduše identifikovatelný, je dobré ho pojmenovat. Stačí kliknout na pole Název reportu.
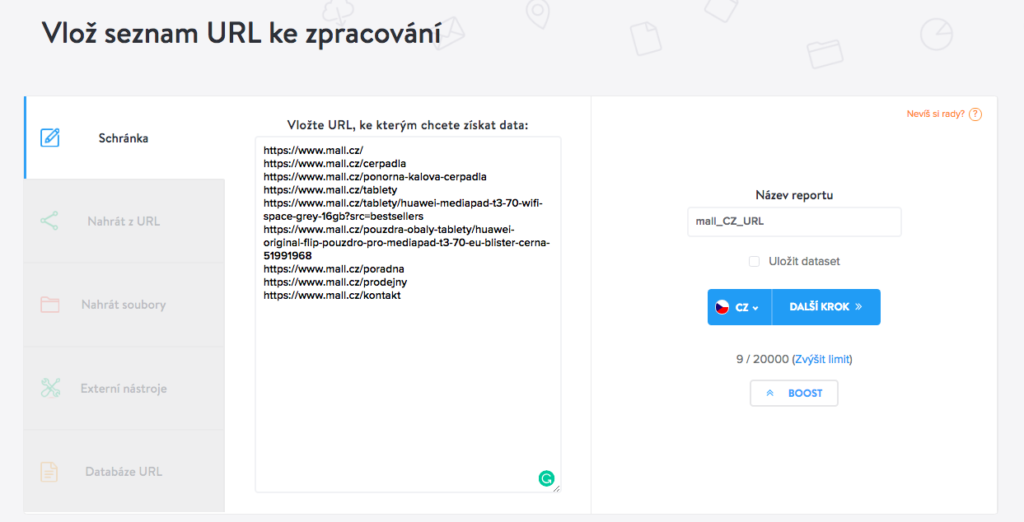
Následně stačí kliknutím na vlajku vybrat zemi, pro kterou chcete získat data. Po kliknutí na Další krok se dostáváte na volbu Mineru.
Volba Mineru a získání dat
V sekci výběru minerů zvolte Fulltext Index Checker. Tento miner se pomocí operátoru info: dotazuje vyhledávače na vložené URL. Pomocí této metody ověřuje, zda je URL indexovaná a zda vyhledávač na výstupu vrací stejnou URL, která byla vložená.
Některé vyhledávače již ale operátor info: nepodporují (například Google) a proto Marketing Miner používá vlastní sadu kroků, kterými zjišťuje, zda je daná URL indexovaná nebo ne.

Poté stiskněte tlačítko Získat data, které vás přesune do sekce zpracování dat. Podle objemu vstupních dat, se podklady zpracují na pozadí a po dokončení odešlou na váš email.

Ukázka výstupu
Popis sloupců
- Input: URL, ke kterým se získávala data.
- Indexed by Google: Detekce, zda je URL vyhledávačem indexována. Navrací buď yes (indexována) nebo canonicalized or not indexed (URL buď není zaindexovaná nebo vyhledávač používá její kanonickou verzi).
- Indexed by Seznam.cz: Detekce, zda je URL vyhledávačem indexována. Navrací buď yes (indexována) nebo no (není indexována).
- Seznam.cz URL in results: Informace o tom, jaká URL při zadání operátoru info: byla vyhledávačem navrácena.
- Seznam.cz Same as input: Porovnání, zda URL na výstupu vyhledávače je stejná, jako na vstupu. Může sloužit k identifikaci funkčnosti kanonizace a mnohé další.
Analýza výstupu
Kontrola neindexovaných stránek
Ve výstupu by vás měly zajímat primárně sloupce Indexed by, které indikují, zda je daná URL indexována v daném vyhledávači (příznak yes/no). Správný postup je vyfiltrovat si seznam neindexovaných stránek a na nich zjišťovat, proč se v indexu vyhledávačů neobjevují a jak by se taková situace dala změnit.
Kontrola kanonizace
Mohou nastat speciální případy, kdy se na výstupu, za použití operátoru info:, objeví jiná URL, než byla vložena. Jde o příznak toho, že vyhledávač o dané URL ví, ale ve výsledcích vyhledávání používá nějakou její kanonickou URL. K detekci těchto URL slouží sloupec Same as input, který vrací buď TRUE v případě, že je URL na výstupu shodná s vloženou URL nebo no, pokud to tak není.